

Boundary Value Analysis (BVA) is a powerful software testing technique that focuses on testing the edge values of input ranges. It targets the extremes, where systems are most likely to encounter errors, rather than checking every possible input.
By concentrating on these boundary points, BVA helps quickly uncover defects that could affect real-world application performance, such as security risks or user experience issues.
When applied effectively, BVA not only improves testing efficiency but also strengthens software reliability, ensuring robust performance across a range of conditions. Since Boundary Value Analysis (BVA) is closely related to Equivalence Class Partitioning (ECP), we'll begin by understanding ECP and then move on to BVA.
What is Boundary Value Analysis?
Boundary Value Analysis (BVA) is a black-box testing technique that targets the input range edges where defects are most likely. It tests both valid and invalid boundary values to ensure the system works as expected under extreme conditions, improving reliability and performance.
In BVA, each partition has minimum and maximum values. Testers check the following for each variable:
- Nominal value
- Minimum value
- Above/below minimum value
- Maximum value
- Invalid boundary value (for invalid partitions)
- Valid boundary value (for valid partitions)
{{cta-image}}
Why is BVA crucial in testing?
BVA is essential because it focuses on boundary conditions, which are often the rise cause of system failures and significant business issues. By targeting these areas, BVA helps testers focus their efforts where they can yield the highest return.
This technique is highly efficient for bug identification, allowing for quicker detection at a lower cost compared to testing broader input ranges. By catching issues early, BVA saves valuable time and resources, preventing problems that might otherwise surface post-release.
Examples of boundaries in software applications
There are multiple boundaries in software applications, such as:
- Numeric input fields: Minimum and maximum values (e.g., age range, quantity selection).
- Date pickers: Start and end dates for a calendar selection.
- Dropdown menus: Test the first and last options on the list.
How Boundary Value Analysis Works
BVA works by testing values at the boundaries of input ranges, rather than testing every possible input. The technique focuses on the edges of equivalence classes—both the minimum and maximum valid values, as well as values just outside the valid range.
Step-by-step process for implementing BVA
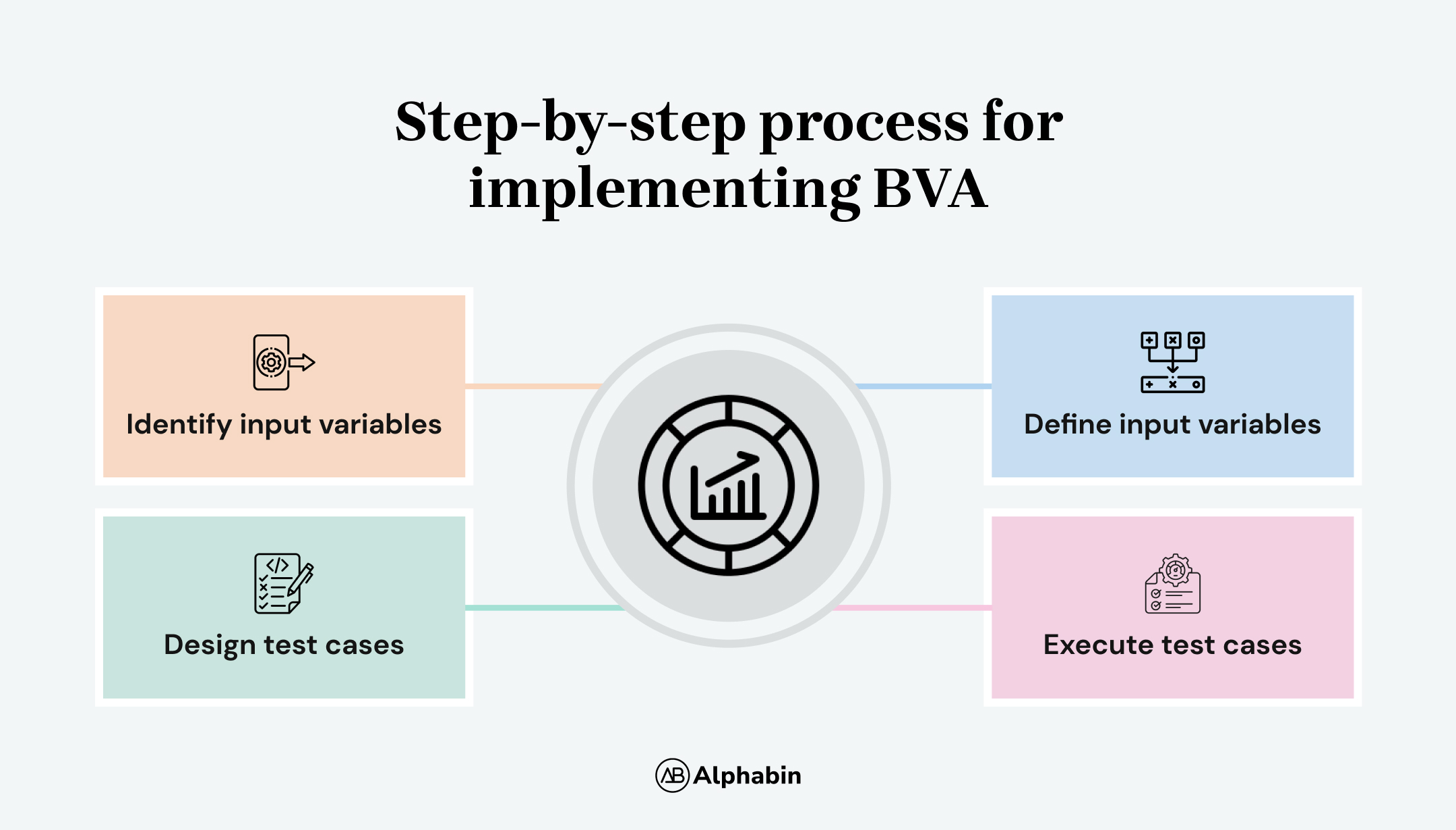
- Identify input variables
List all software functionalities that require user input. - Define input variables
Determine the valid and invalid ranges for each input variable. - Design test cases
Create test cases that target the following boundary values:- Valid boundaries (minimum, maximum)
- Values just inside the valid boundaries
- Values just outside the valid boundaries (minimum -1 and maximum + 1)
- Invalid values (e.g., negative numbers where only positives are allowed)
- Execute test cases
Run the designed test cases and analyze the software’s behavior.
Test Scenarios and Test Cases for Boundary Value Analysis
Test scenarios and cases are key in implementing BVA in software testing. A test scenario defines input values and expected outcomes. For example, testing with the age 18 to check if the system accepts it as valid. A test case performs the scenario and verifies the result.
For BVA, test cases involve both valid and invalid input values, including boundary values like 18, 19, 59, and 60, and values just outside these ranges. Testing various combinations ensures the system handles all cases, validating the application's robustness.
Advantages of Boundary Analysis Testing
The BVA technique provides multiple advantages or benefits for software testing, such as improved test coverage, identifying potential errors, cost-saving, and time-effectiveness. Let's look at them in detail.

Improved test coverage
Boundary value analysis optimizes test coverage by pinpointing pivotal and only needed input ranges, making sure that the testing efforts are concentrated where they matter the most.
Efficiency in identifying potential errors
BVA operates with surgical precision, validating boundaries where errors are most likely to be found. Directing attention to these crucial junctures, drastically increases the chances of identifying and rectifying defects associated with input validation.
Cost-effectiveness of BVA
Time is money, and boundary value analysis in software testing proves to be a great testing investment. Through its early intervention strategy, BVA speeds up error resolution and prevents costly fixes later on. It’s like stopping a leak before it floods the house.
Time-saver
Time is incredibly valuable in software engineering. By quickly identifying key areas to focus on, BVA helps teams work more efficiently, saving time for both testers and developers. This efficient approach means teams can use their time wisely, concentrating on improving the software instead of getting stuck fixing avoidable issues.
By understanding these advantages, it becomes clear why Boundary Value Analysis is a preferred testing technique for many software development teams.
Common Mistakes and How to Avoid Them
While boundary value analysis (BVA) is an effective technique, there are common mistakes testers may make. In this section, we’ll explore these pitfalls and share best practices to help you avoid them, ensuring more accurate and reliable test results.
Typical mistakes made during BVA
- Overlooking invalid boundary values
Testers sometimes ignore the invalid boundary values, which can lead to untested paths in the application, which can later be costly to fix or, worse, be found by a user. - Failing to test boundaries for all input fields
It’s common to miss testing boundaries for some input fields, especially when the application has a large number of inputs, such as a FinTech back office platform. - Not considering user experience
Selecting boundary values without considering how the end-user will interact with the application can result in a less effective test, and the product will be made without the user’s consideration.
Best practices for avoiding these mistakes
By following these best practices, testers can avoid common mistakes and enhance the effectiveness of Boundary Value Analysis in their software testing process.
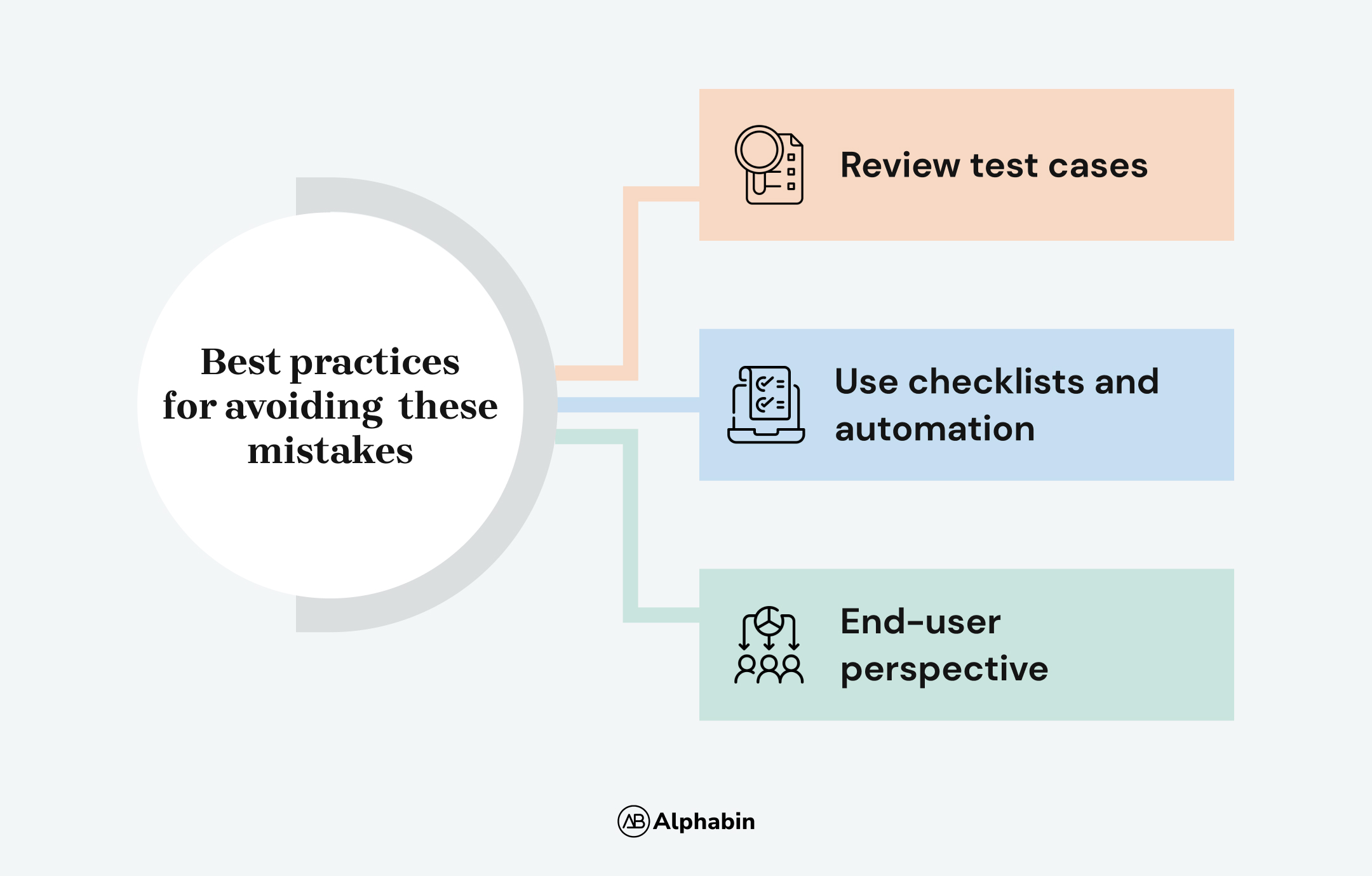
- Review test cases
- Conduct a thorough analysis of the input domain.
- Get your test cases reviewed, and make sure that the test cases cover both valid and invalid boundary values.
- Use checklists and automation
- Use checklists and automated tools to ensure no input field is overlooked.
- Develop a comprehensive test case design that includes all input fields.
- End-user perspective
- Incorporate the end-user perspective into test planning.
- Simulate real-world usage scenarios to determine practical boundary values.
Various Techniques for Boundary Testing
Boundary analysis testing can be implemented with multiple techniques that will boost its effectiveness and results.
Automated Boundary Value Generation
- Use tools to generate boundary values automatically.
- Integrate them into the testing framework.
- Automate testing for boundary values before manual validation.
Manual Approach Before Automation
Before automating the process, let’s understand the manual steps involved in BVA:
- Identify the input field and its valid range (e.g., age between 18-60).
- Manually enter boundary values (18, 19, 59, 60) and verify behavior.
After the manual verification, implement BVA in your automation code:
Technology used:
- Programming language: Python
- Framework: Selenium
Outcome of this BVA automation:
- Initialization
- Initializes Chrome WebDriver with a 10-second wait for element location.
- Boundary values
- The age_boundaries list contains the values [18, 19, 59, 60].
- Navigation
- The script navigates to the web form at “http://demo.alphabin.co”.
- Testing loop
- For each age boundary value:
- Clears the input field with ID "age".
- Enters the current age value.
- Clicks the submit button with ID "submit-button".
- Waits for the result and prints the output.
- For each age boundary value:
- Expected output
- The output will be printed for each age boundary value.
- Successful submissions (e.g., “Form submitted successfully!”).
- Error messages (e.g., “Invalid age. Please enter a valid age.”).
- The output will be printed for each age boundary value.
Single fault assumption technique
The Single Fault Assumption technique simplifies testing by focusing on one variable at a time:
- Hold all but one variable constant
- Keep all but one variable at its extreme value, allowing only one to vary.
- Keep all but one variable at its extreme value, allowing only one to vary.
- Test with varying variables
- Test the system with the remaining variable at both its minimum and maximum values.
- Test the system with the remaining variable at both its minimum and maximum values.
- Why use this approach?
- It reduces the number of test cases needed by assuming a single fault causes failure.
- Simplifies functional testing while providing valuable insights into system behavior.
Let’s take a look at the code snippet for the single fault assumption technique:
The following example is done with Python language.
Combining Equivalence Partitioning (ECP) and Boundary Value Analysis (BVA)
When designing test cases, combining ECP and BVA techniques can enhance test coverage and provide thorough testing.
- Equivalence Partitioning (ECP)
- Divide the input data into equivalent partitions based on shared characteristics.
- For example, if an input field accepts ages, we can create partitions like:
- Partition 1: Ages below 18 (Invalid)
- Partition 2: Ages between 18 and 60 (Valid)
- Partition 3: Ages above 60 (Invalid)
- Boundary Value Analysis (BVA)
- Focus on the boundary values of each partition.
- Example for age (18-60):
- Test with 18, 19, 59, 60, and values just above/below (17, 61).
- Combining ECP and BVA
- Let’s combine all the above-given examples and create manual test cases based on ECP and BVA.
Automating the combination of BVA and ECP
Now that we've covered the manual approach of combining ECP with BVA, let's explore how to automate this process.
Technology:
- Programming language: Python
- Framework: Selenium
{{cta-image-second}}
Conclusion
Quick recap: In the blog, we covered the concept of BVA, its importance in quality assurance, the methodologies for its implementation, its benefits, common mistakes while using BVA, and various techniques that will help you boost your results from using this amazing testing technique.
Final thoughts: Boundary values testing plays a crucial role in enhancing your testing approach for any platform in any domain. Alphabin is the best testing services provider company in the global digital world, and that helps to ensure your software is bug-free. By focusing on the most likely areas for defects to occur, helps testers cover more tests in the limited testing time they get.


.svg)












.svg)